Buffer Overflow attacks explained - BoF
General Introduction
A buffer overflow occurs when a program or process attempts to write more data to a fixed length block of memory than the buffer is supposed to hold. By sending a carefully crafted input to an application, an attacker can cause the application to execute arbitrary code, possibly taking over the machine. Buffer overflows can often be triggered by malformed inputs. For example, if one assumes all inputs will be smaller than a certain size and the buffer is created to be that size, then an anomalous transaction that produces more data could cause it to write past the end of the buffer. A buffer overflow occurs when data written to a buffer also corrupts data values in memory addresses adjacent to the destination buffer due to insufficient bounds checking. This can occur when copying data from one buffer to another without first checking that the data fits within the destination buffer.
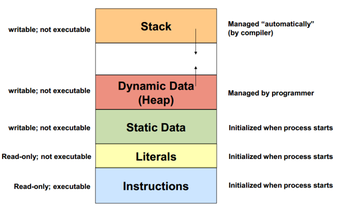
STACK vs HEAP
A data buffer (or just buffer) is a region of a memory used to temporarily store data while it is being moved from one place to another. Typically, the input the data of a process is stored in a buffer as it is retrieved from its input device (such as a microphone or a keyboard). However, a buffer may be used when moving data between processes within a computer.
Heap is a region of process’s memory which is used to store dynamic variables. These variables are allocated using malloc() and calloc() functions and resize using realloc() function, which are inbuilt functions of C programming language. These variables can be accessed globally and once we allocate memory on heap it is our responsibility to free that memory space after use. There are two situations which can result in heap overflow:
- If we continuously allocate memory and we do not free that memory space after use it may result in
memory leakage– memory is still being used but not available for other processes. - If we dynamically allocate large number of variables.
Stack is a special region of our process’s memory which is used to store local variables used inside the function, parameters passed through a function and their return addresses. Whenever a new local variable is declared it is pushed onto the stack. All the variables associated with a function are deleted and memory they use is freed up, after the function finishes running. The user does not have any need to free up stack space manually. Stack is Last-In-First-Out data structure.
In our computer’s memory, stack size is limited. If a program uses more memory space than the stack size then stack overflow will occur and can result in a program crash. There are two cases in which stack overflow can occur:
- If we declare large number of local variables or declare an array or matrix or any higher dimensional array of large size can result in overflow of stack.
- If function recursively call itself infinite times then the stack is unable to store large number of local variables used by every function call and will result in overflow of stack.
Pros/benefits of using the Stack:
- Helps you to manage the data in a Last In First Out(LIFO) method which is not possible with Linked list and array.
- When a function is called the local variables are stored in a stack, and it is automatically destroyed once returned.
- A stack is used when a variable is not used outside that function.
- It allows you to control how memory is allocated and deallocated.
- Stack automatically cleans up the object.
- Not easily corrupted
- Variables cannot be resized.
Pros/benefit of using Heap memory are:
- Heap helps you to find the greatest and minimum number
- Garbage collection runs on the heap memory to free the memory used by the object.
- Heap method also used in the Priority Queue.
- It allows you to access variables globally.
- Heap does not have any limit on memory size.
Cons/Drawbacks of using Stack memory are:
- Stack memory is very limited.
- Creating too many objects on the stack can increase the risk of stack overflow.
- Random access is not possible.
- Variable storage will be overwritten, which sometimes leads to undefined behavior of the function or program.
- The stack will fall outside of the memory area, which might lead to an abnormal termination.
Cons/drawbacks of using Heaps memory are:
- It can provide the maximum memory an OS can provide
- It takes more time to compute.
- Memory management is more complicated in heap memory as it is used globally.
- It takes too much time in execution compared to the stack.
When to use the Heap and when to use the Stack? You should use heap when you require to allocate a large block of memory. For example, you want to create a large size array or big structure to keep that variable around a long time then you should allocate it on the heap.
However, If you are working with relatively small variables that are only required until the function using them is alive. Then you need to use the stack, which is faster and easier.
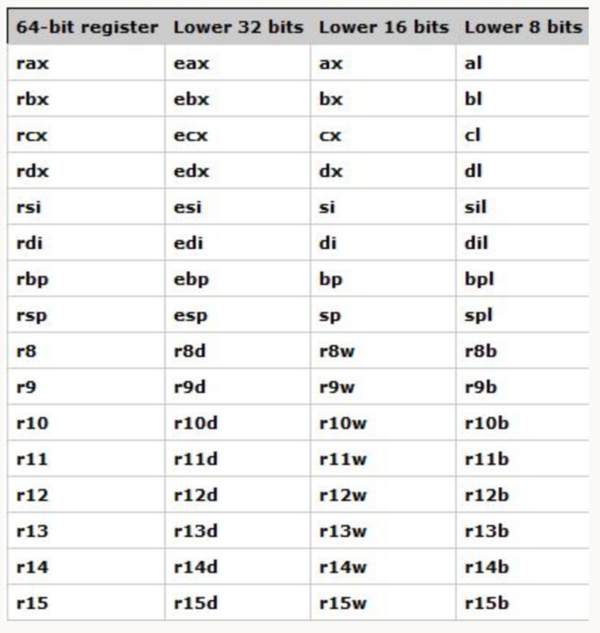
Intel based x86 CPU registers
The memory space of a microprocessor is expected to be byte-addressable. When we talk about a processor being 32-bit or 64-bit, we are referring to the width of the CPU registers. When a CPU has a 32-bit address bus this means that it can access a total of 2^32 addresses, each with a size of 1 byte. In case of a 64-bit architecture, the CPU can access to a total of 2^64 addresses. Each CPU has a set of registers that are accessible when required. Registers could be thought of as temporary variables used by the CPU to obtain and store data. There are registers that have a specific function, while there are others that only serve as stated above, to obtain and store data. In a CPU there are a lot of registers to store different information, we are going to focus on GPRs (General Purpose Registers). For a buffer overflow attack, we just need to know the EIP, ESP and the EBP.
- EIP instruction pointer (Extended Instruction Pointer): It contains the address of the next instruction to be executed. If this address points to the malicious code, it is a good vector attack point. Our prime focus is on EIP register since we need to hijack execution flow. EIP read only register, so we cannot assign the memory address of the instruction to be executed to it.
- ESP stack pointer: ESP points to the top of the stack at lower memory location.
- EBP base pointer (Extended Base Pointer): EBP pointer tells you where you are in the stack
- ESI source index
- EDI destination index
- EAX accumulator
- EBX base
- ECX counter
- EDX data
Depending on the processor bits (32 or 64 bits), the nomenclature is different:
Stack based Buffer Overflow in X86 architecture
For an easy explanation of a buffer overflow attack, some pictures will be used for the explanation. Of course, these pictures are a minimalist view of a stack, but they explain well in a graphical way the principle of a buffer overflow attack.
A general view of a stack is similar to this one:

If a certain amount of memory is reserved for a variable (For example, to store the value of a password or a username of a frontend), the stack will look similar to this:

But if the variable has more bytes than the reserved memory of the buffer, the stack will look like this:

The returned address (which points to the address of the next instruction to execute) will be overwritten. Knowing this, it is possible to assign the memory address of the next instruction to the return addres (It is possible to decide that new address). Remember that when the returned address is popped out of the stack, the returned address (the address of the next instruction) is going to be kept in the EIP register. So, by changing the returned address we will be overwritten the EIP and we will be changing the flow of the program and we will be executing an arbitrary code.
Endianness
Endianness refers to the way bytes are ordered when a data item with a size bigger than 1 byte is placed in memory or transmitted over a communication interface.
The way to represent and store the values in the memory is in Endianness, which can be of two different types:
- Big-endian: The bytes are ordered with the most significant byte placed at the lowest address.
- Little-endian: The bytes are ordered with the least significant byte placed at the lowest address.
A comparison of how data items are placed in memory using little-endian and big-endian is shown in the picture below. For simplicity, we are using memory with 8 addresses. Data 1 is stored first and as a 32-bit variable, it takes the first four memory addresses (remember each address can store 1 byte). The lowest memory address for Data 1 is address 0. In the case of little-endian format, Data 1 is stored with its least significant byte (0x29) at the lowest address, the next byte (0xA4) at the following address, and so on. In the case of big-endian format, Data 1 is stored with its most significant byte (0x65) at address 0, the next byte (0x73) at address 1, and so on.
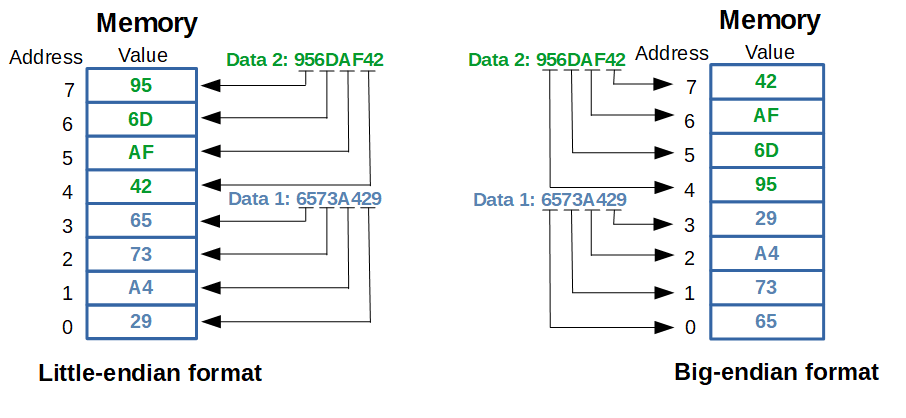
The endianness does not have a big impact on the microprocessor hardware implementation. As the endianness is relevant only on the operations that access data from the memory.
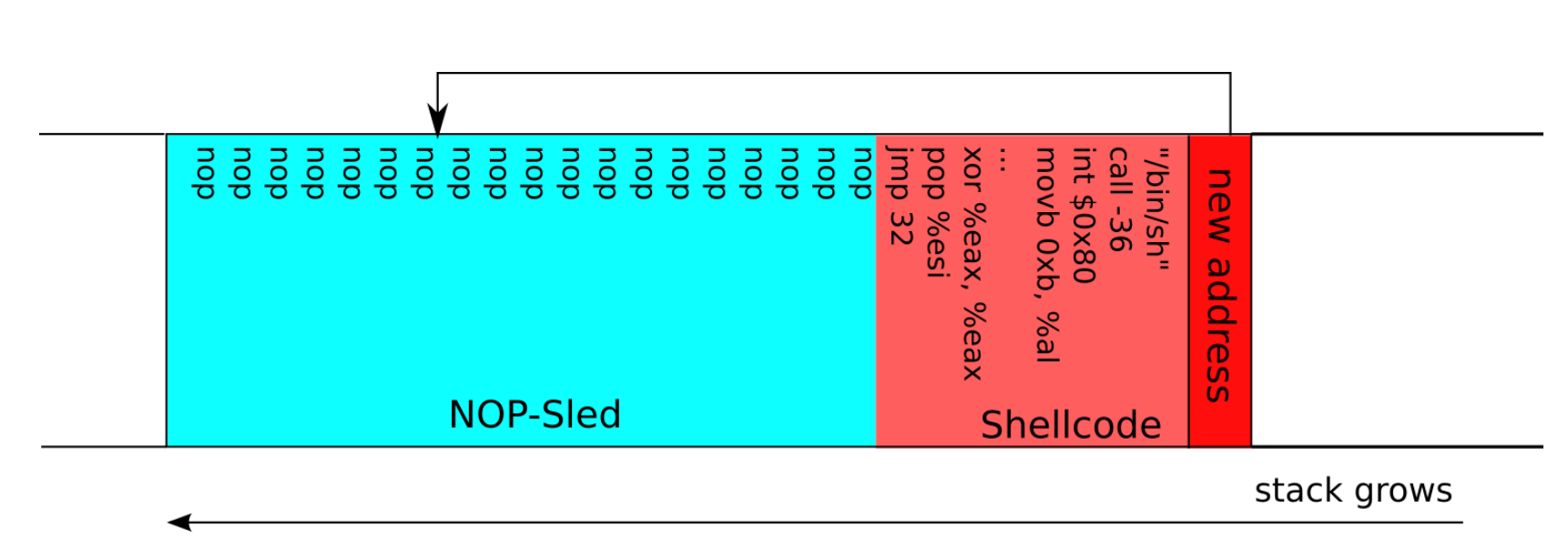
NOP - No Operation computer instruction
The NOP is an assembly language instruction that does nothing. If a program encounters a NOP it will simply jump to the next instruction. The NOP is usually represented in hexadecimal as 0x90, on x86 systems.
NOP-sled is a technique used during buffer overflows. Its purpose is to fill either a large or small portion of the NOPS stack. This will allow us to control which instruction we want to execute, which will normally be placed after the NOP-sled (A shellcode, for example).
The reason for this is because maybe the buffer overflow in question in the program needs a specific size and address because it will be the one that the program is expecting. Or it can also make it easier for us to get the EIP to point to our payload/shellcode.
GDB Commands
pattern offset $eipProtections
- ASRL (Address Space Layout Randomization)